Behind the Shield: Unmasking Scudo's Defenses
When writing an exploit for a memory corruption vulnerability, knowing the heap allocator internals is often required to shape the heap as desired. Following our previous blogpost focusing on jemalloc (new), this article will dive into another one of Android libc allocators: Scudo.
Looking to improve your skills? Discover our trainings sessions! Learn more.
Scudo is part of LLVM (https://llvm.org/docs/ScudoHardenedAllocator.html) and is designed as an hardened allocator providing mitigation against heap-based vulnerabilities. It is the default allocator in Android since version 11 and the name "scudo" comes from the name "shield" in italian.
Android advertises Scudo as a "dynamic user-mode memory allocator, or heap allocator, designed to be resilient against heap-related vulnerabilities (such as heap-based buffer overflow, use after free, and double free) while maintaining performance" (https://source.android.com/docs/security/test/scudo?hl=en). All references are given against this revision of source code: https://android.googlesource.com/platform/external/scudo/ commit 93fc3ad0cf853a2c6439eb46fa6bd56ad3966452. All relevant files are under the standalone/ directory.
Scudo is a generic allocator, designed to be modular and highly configurable. All tests and observations were done on a Google Pixel7 phone running Android 13. As we explore this topic further, it's worth noting that Trenchant (blogpost)and ItsIronicIInsis (BSides Canberra conference) recently shared their thoughts on the matter as well. You might find their perspectives valuable alongside ours.
Scudo high overview and terminology
Scudo uses its own terminology and definitions, and some terms are specific to it. The allocator is designed generically and exists across various operating systems and architectures (32 and 64 bits). All information presented here is situated within the context of arm 64-bits Android 13. Under a different operating system, "your mileage may vary".
There exists two allocators, primary and secondary. The primary manages allocation smaller than 0x10010 bytes and secondary manages all other allocations.
Scudo uses internally the notion of Block. A block is constitued by a header and a chunk. The Chunk is the memory region returned by the malloc function. The header contains metadata, and has a size of 0x10 bytes (8 significant bytes and 8 null bytes used for alignment). Consequently, malloc(n) requires (n+0x10) bytes to accomodate both the header and the data.
Allocations are categorized according to their respective sizes, called ClassId. The standalone/size_class_map.h file provides various size classification. For Android 64-bit systems, Classes are:
static constexpr u32 Classes[] = {
0x00020, 0x00030, 0x00040, 0x00050, 0x00060, 0x00070, 0x00090, 0x000b0,
0x000c0, 0x000e0, 0x00120, 0x00160, 0x001c0, 0x00250, 0x00320, 0x00450,
0x00670, 0x00830, 0x00a10, 0x00c30, 0x01010, 0x01210, 0x01bd0, 0x02210,
0x02d90, 0x03790, 0x04010, 0x04810, 0x05a10, 0x07310, 0x08210, 0x10010,
};
Those size are the maximum for a block. Any block is referenced with its classId. The classId starts at index 1. As an example a malloc(0x12) will need a block of size 0x22, and is served with a classId 2. Allocation larger than 0x10010 fall under the secondary allocator.
Same ClassId allocations are grouped in the same zone, called "Region". Regions are indexed in alignment with the ClassId numbering, e.g. Region 1 for ClassId1. For instance, Region 1 accommodates blocks up to 0x20 bytes in size, Region 2 caters to sizes up to 0x30 bytes, and so forth. Region 0 has a very distinct significance. Region 0 stores the lists of free blocks, called TransferBatch 1.
TransferBatch records a list of free blocks of the same ClassId. During the storage of pointers within freelists or caches, pointer values are subjected to compaction based on the subsequent computation in standalone/allocator_config.h:
// Defines the type and scale of a compact pointer. A compact pointer can
// be understood as the offset of a pointer within the region it belongs
// to, in increments of a power-of-2 scale.
// eg: Ptr = Base + (CompactPtr << Scale).
Where 'Scale' is assigned the value of SCUDO_MIN_ALIGNMENT_LOG. This value is set in the Android.bp file located at the project root 2:
// Android assumes that allocations of multiples of 16 bytes
// will be aligned to at least 16 bytes.
"-DSCUDO_MIN_ALIGNMENT_LOG=4",
The primary allocator
Scudo is highly configurable, we follow here the configuration for Android 64. The initialization starts within standalone/primary64.h, located in the 'scudo' namespace. In this header file, a configuration of the type SizeClassAllocator64` is established, employing values extracted from the AndroidConfig structure defined in standalone/allocator_config.h.
Initialisation of the heap
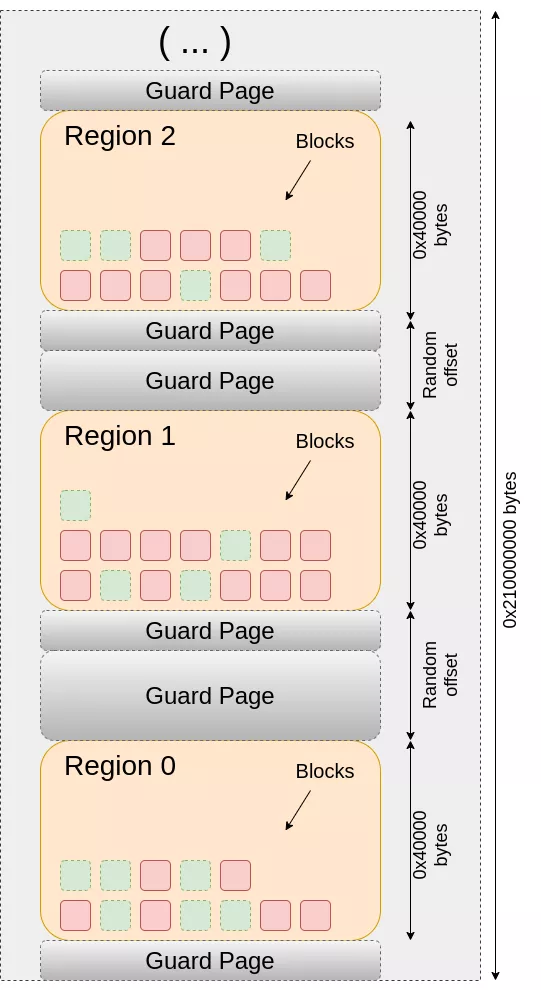
A memory region of size NumClasses * 2^RegionSizeLog bytes is allocated, partitioned into regions of equivalent sizes. For security considerations, each region is encapsulated between two guard pages to prevent linear read or write overflows from allocations.
In the case of AndroidConfig, RegionSizeLog is set to 28, and we have 33 classes (32 classId plus Region 0) resulting in an allocation of 8,858,370,048 bytes. This allocation behavior is observed for a given process:
# cat /proc/$(pidof myprogram)/maps
(...)
7acf76d000-7acf76e000 rw-p 000a1000 fd:05 2118 /system/lib64/libc++.so
7acf76e000-7acf771000 rw-p 00000000 00:00 0 [anon:.bss]
7acf782000-7acf785000 ---p 00000000 00:00 0
7acf785000-7acf7c5000 rw-p 00000000 00:00 0 [anon:scudo:primary]
7acf7c5000-7adf784000 ---p 00000000 00:00 0
7adf784000-7adf7c4000 rw-p 00000000 00:00 0 [anon:scudo:primary]
7adf7c4000-7aff78c000 ---p 00000000 00:00 0
7aff78c000-7aff7cc000 rw-p 00000000 00:00 0 [anon:scudo:primary]
7aff7cc000-7bcf791000 ---p 00000000 00:00 0
7bcf791000-7bcf7d1000 rw-p 00000000 00:00 0 [anon:scudo:primary]
7bcf7d1000-7cdf782000 ---p 00000000 00:00 0
7cdf782000-7cdf7bf000 r--p 00000000 07:30 38 /apex/com.android.runtime/lib64/bionic/libc.so
(...)
We observe regions (rw-) separated by guard pages (---).3
Each region is instantiated upon the first allocation of its respective class size. Initially, each region holds a size of 0x40000 bytes MapSizeIncrement = 1UL << 18; as detailed in standalone/allocator_config.h. When all blocks in a region are allocated, the upper guard page is removed, the region's size is enlarged by 0x40000, and a new guard page is shifted at the top.
The gap between two consecutive regions is randomized (as governed by EnableRandomOffset = true; within the Android configuration).
Allocate: from malloc to pointer
When a program invokes the malloc() function, a series of operations is initiated to fulfill the request. For efficiency, the library first seeks a block within the thread's local cache. If the cache is devoid of available blocks, the library proceeds to replenish it through the use of a TransferBatch (freelist) stored in Region0 (shared cache). In the event that no TransferBatch is available, the library generates multiple batches (for efficiency) and returns one.
The file standalone/combined.h shows the first step. malloc() calls allocate:
NOINLINE void *allocate(uptr Size, Chunk::Origin Origin,
uptr Alignment = MinAlignment,
bool ZeroContents = false) NO_THREAD_SAFETY_ANALYSIS {
initThreadMaybe();
(...)
if (LIKELY(PrimaryT::canAllocate(NeededSize))) {
ClassId = SizeClassMap::getClassIdBySize(NeededSize);
DCHECK_NE(ClassId, 0U);
bool UnlockRequired;
auto *TSD = TSDRegistry.getTSDAndLock(&UnlockRequired);
Block = TSD->getCache().allocate(ClassId); [1]
(...)
}
if (UNLIKELY(ClassId == 0)) {
Block = Secondary.allocate(Options, Size, Alignment, &SecondaryBlockEnd,
FillContents);
}
(...)
const uptr BlockUptr = reinterpret_cast<uptr>(Block);
const uptr UnalignedUserPtr = BlockUptr + Chunk::getHeaderSize();
const uptr UserPtr = roundUp(UnalignedUserPtr, Alignment);
(...)
Chunk::UnpackedHeader Header = {}; [2]
(...)
Header.ClassId = ClassId & Chunk::ClassIdMask;
Header.State = Chunk::State::Allocated;
Header.OriginOrWasZeroed = Origin & Chunk::OriginMask;
Header.SizeOrUnusedBytes =
(ClassId ? Size : SecondaryBlockEnd - (UserPtr + Size)) &
Chunk::SizeOrUnusedBytesMask;
Chunk::storeHeader(Cookie, Ptr, &Header);
(...)
return TaggedPtr;
}
The separation between primary and secondary allocator is made early. The function then asks the TSD [1] (Thread Specific Data) to allocate a block of a given ClassId. By default, multiple TSD are created, as it can be seen in standalone/allocator_config.h
using TSDRegistryT = TSDRegistrySharedT<A, 8U, 2U>; // Shared, max 8 TSDs.
template <class Allocator, u32 TSDsArraySize, u32 DefaultTSDCount>)
The header [2] is defined as this (in bit size):
struct UnpackedHeader {
uptr ClassId : 8;
u8 State : 2;
// Origin if State == Allocated, or WasZeroed otherwise.
u8 OriginOrWasZeroed : 2;
uptr SizeOrUnusedBytes : 20;
uptr Offset : 16;
uptr Checksum : 16;
};
And here is a header:
[Pixel 7::myprogram ]-> a = malloc(0x22)
"0xb40000772459dcd0"
[Pixel 7::myprogram ]-> dump_mem(ptr('0xb40000772459dcd0').sub(0x10), 0x10)
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
b40000772459dcc0 03 21 02 00 00 00 28 6c 00 00 00 00 00 00 00 00 .!....(l........
[Pixel 7::myprogram ]->
We can see a classId 3, a state 1 (allocated), no origin, a 0x22 size, null offset and a checksum of 0x286c.
Although this is a CRC32, it is reduced to 16 bytes as seen in the computeChecksum function in standalone/chunk.h:
return static_cast<u16>(Crc ^ (Crc >> 16));
This checksum is used at deallocation, in order to detect modification of the header.
Finally the pointer is tagged, and returned to user.
The TSD local cache
We now have to dive in the TSD->getCache().allocate(ClassId); to see how the request is handled:
void *allocate(uptr ClassId) {
DCHECK_LT(ClassId, NumClasses);
PerClass *C = &PerClassArray[ClassId];
if (C->Count == 0) {
if (UNLIKELY(!refill(C, ClassId))) [1]
return nullptr;
DCHECK_GT(C->Count, 0);
}
// We read ClassSize first before accessing Chunks because it's adjacent to
// Count, while Chunks might be further off (depending on Count). That keeps
// the memory accesses in close quarters.
const uptr ClassSize = C->ClassSize;
CompactPtrT CompactP = C->Chunks[--C->Count];
Stats.add(StatAllocated, ClassSize);
Stats.sub(StatFree, ClassSize);
return Allocator->decompactPtr(ClassId, CompactP);
}
For each TSD, there is a cache associated with a given classId. The pointer is automatically decompacted and returned to the calling function. If the cache is empty, it is automatically populated with the refill [1] function:
NOINLINE bool refill(PerClass *C, uptr ClassId) {
initCacheMaybe(C);
TransferBatch *B = Allocator->popBatch(this, ClassId);
if (UNLIKELY(!B))
return false;
DCHECK_GT(B->getCount(), 0);
C->Count = B->getCount();
B->copyToArray(C->Chunks);
B->clear();
destroyBatch(ClassId, B);
return true;
}
The refill function retrieves a TransferBatch and efficiently copies it into the TSD's local cache. The size of a TransferBatch is equal to half of the cache size, thus preventing rapid cache overflow in cases where a thread engages in allocation followed by multiples deallocations. Unlike local caches, TransferBatches are shared among all threads and are stored in the Region 0.
The BatchGroups
If popBatch doesn't have any TransferBatch remaining, the populateFreeListAndPopBatch function is run:
(...)
static const u32 MaxNumBatches = SCUDO_ANDROID ? 4U : 8U;
// Refill the freelist and return one batch.
NOINLINE TransferBatch *populateFreeListAndPopBatch(CacheT *C, uptr ClassId,
RegionInfo *Region)
REQUIRES(Region->MMLock) EXCLUDES(Region->FLLock) {
(...)
const u32 NumberOfBlocks =
Min(MaxNumBatches * MaxCount,
static_cast<u32>((Region->MemMapInfo.MappedUser -
Region->MemMapInfo.AllocatedUser) /
Size));
(...)
for (u32 I = 0; I < NumberOfBlocks; I++, P += Size)
ShuffleArray[I] = compactPtrInternal(CompactPtrBase, P);
(...)
u32 N = 1;
uptr CurGroup = compactPtrGroup(ShuffleArray[0]);
for (u32 I = 1; I < NumberOfBlocks; I++) {
if (UNLIKELY(compactPtrGroup(ShuffleArray[I]) != CurGroup)) {
shuffle(ShuffleArray + I - N, N, &Region->RandState);
pushBlocksImpl(C, ClassId, Region, ShuffleArray + I - N, N,
/*SameGroup=*/true);
N = 1;
CurGroup = compactPtrGroup(ShuffleArray[I]);
} else {
++N;
}
}
(...)
TransferBatch *B = popBatchImpl(C, ClassId, Region);
DCHECK_NE(B, nullptr);
(...)
The function performs a series of checks (not shown here) on the available space within the Region and, if necessary, expands it. Afterward, an array is built, housing blocks that are shuffled and segmented into several TransferBatches.
In the general case, four TransferBatches are generated, and one of them is returned. This particular TransferBatch is promptly employed to populate the cache of the calling thread, thereby facilitating the provisioning of the requested allocation.
What is the cache size
Each of these functions employs a quantity 'MaxCached' to compute the TransferBatch size, the size of the TSD's local cache, and so forth. This value is subject to variation depending on the ClassId.
The function getMaxCached determines this value. The computation of the maximum number of pointers cached is governed by the following formula (from standalone/size_class_map.h):
N = (1U << Config::MaxBytesCachedLog) / static_cast<u32>(Size);
Max(1U, Min<u32>(Config::MaxNumCachedHint, N))
or, in a pythonic way with values extracted from the configuration:
int(max(1,min(13,(1<<13)/BlockSize)))
This gives us the following values :
BlockSize | classId | MaxCached
0x20 | 1 | 13
0x30 | 2 | 13
0x40 | 3 | 13
0x50 | 4 | 13
(...)
0x250 | 14 | 13
0x320 | 15 | 10
0x450 | 16 | 7
0x670 | 17 | 4
0x830 | 18 | 3
0xa10 | 19 | 3
0xc30 | 20 | 2
0x1010 | 21 | 1
0x1210 | 22 | 1
(...)
0x10010 | 32 | 1
Randomisation of blocks
Scudo employs a block shuffling mechanism that occurs prior to copying these blocks into TransferBatch. To facilitate a more intuitive understanding of this allocation process, we've developed a visualization tool called "heapview." This tool offers a graphical representation, using dots "." to signify free blocks and hashes "#" to signify allocated blocks. The width of each line corresponds to 4 times the MaxCached value, which amounts to 52 blocks for the requested size.
Through the heapview tool, we can observe how Scudo randomizes allocations within these four TransferBatches until they are fully occupied. Once these initial TransferBatches are filled, Scudo generates an additional set of four TransferBatches, and allocations are randomized within this second set, effectively filling the next line of the visualization.

Deallocate : from free to cache
The deallocation of a chunk entails several steps. Verifications are conducted on both the header and the pointer, after which the pointer is stored within the local cache. In the event that the local cache is full, it is half-emptied (oldest entries first), and these pointers are moved back into a TransferBatch for reuse by any TSD.
Here is the path following a free() function. It starts in the standalone/combined.h file with the deallocate function:
NOINLINE void deallocate(void *Ptr, Chunk::Origin Origin, uptr DeleteSize = 0,
UNUSED uptr Alignment = MinAlignment) {
(...)
if (UNLIKELY(!isAligned(reinterpret_cast<uptr>(Ptr), MinAlignment)))
reportMisalignedPointer(AllocatorAction::Deallocating, Ptr);
void *TaggedPtr = Ptr;
Ptr = getHeaderTaggedPointer(Ptr);
Chunk::UnpackedHeader Header;
Chunk::loadHeader(Cookie, Ptr, &Header);
if (UNLIKELY(Header.State != Chunk::State::Allocated))
reportInvalidChunkState(AllocatorAction::Deallocating, Ptr);
const Options Options = Primary.Options.load();
if (Options.get(OptionBit::DeallocTypeMismatch)) {
if (UNLIKELY(Header.OriginOrWasZeroed != Origin)) {
// With the exception of memalign'd chunks, that can be still be free'd.
if (Header.OriginOrWasZeroed != Chunk::Origin::Memalign ||
Origin != Chunk::Origin::Malloc)
reportDeallocTypeMismatch(AllocatorAction::Deallocating, Ptr,
Header.OriginOrWasZeroed, Origin);
}
}
const uptr Size = getSize(Ptr, &Header);
if (DeleteSize && Options.get(OptionBit::DeleteSizeMismatch)) {
if (UNLIKELY(DeleteSize != Size))
reportDeleteSizeMismatch(Ptr, DeleteSize, Size);
}
quarantineOrDeallocateChunk(Options, TaggedPtr, &Header, Size);
}
This function executes sanity checks before deallocation. The Chunk::loadHeader function extracts the header in the appropriate structure and validates the checksum, aborting the process in case of error. Other checks depends on options defined in the standalone/flags.inc file.
The SCUDO framework uses a quarantine mechanism in order to retain free chunks before reuse. This could prevent some Use-After-Free scenarios, where attacker wouldn't be able to reallocate a freed chunk with controlled data. Under Android, however, the quarantine is disabled, as a config value used in flags.inc says:
SCUDO_FLAG(int, quarantine_size_kb, 0,
"Size (in kilobytes) of quarantine used to delay the actual "
"deallocation of chunks. Lower value may reduce memory usage but "
"decrease the effectiveness of the mitigation.")
A freed pointer is immediately reused, as shown by thoses commands:
[Pixel 7::myprogram ]-> a = malloc(0x200)
"0xb4000076d4447000"
[Pixel 7::myprogram ]-> free(ptr(a))
[Pixel 7::myprogram ]-> a = malloc(0x200)
"0xb4000076d4447000"
[Pixel 7::myprogram ]->
The quarantineOrDeallocateChunk function is briefly presented here:
void quarantineOrDeallocateChunk(const Options &Options, void *TaggedPtr,
Chunk::UnpackedHeader *Header,
uptr Size) NO_THREAD_SAFETY_ANALYSIS {
void *Ptr = getHeaderTaggedPointer(TaggedPtr);
Chunk::UnpackedHeader NewHeader = *Header;
// If the quarantine is disabled, the actual size of a chunk is 0 or larger
// than the maximum allowed, we return a chunk directly to the backend.
// This purposefully underflows for Size == 0.
const bool BypassQuarantine = !Quarantine.getCacheSize() ||
((Size - 1) >= QuarantineMaxChunkSize) ||
!NewHeader.ClassId;
if (BypassQuarantine)
NewHeader.State = Chunk::State::Available;
(...)
if (BypassQuarantine) {
if (allocatorSupportsMemoryTagging<Config>())
Ptr = untagPointer(Ptr);
void *BlockBegin = getBlockBegin(Ptr, &NewHeader);
const uptr ClassId = NewHeader.ClassId;
if (LIKELY(ClassId)) {
bool UnlockRequired;
auto *TSD = TSDRegistry.getTSDAndLock(&UnlockRequired);
const bool CacheDrained =
TSD->getCache().deallocate(ClassId, BlockBegin);
(...)
if (CacheDrained)
Primary.tryReleaseToOS(ClassId, ReleaseToOS::Normal);
} else {
if (UNLIKELY(useMemoryTagging<Config>(Options)))
storeTags(reinterpret_cast<uptr>(BlockBegin),
reinterpret_cast<uptr>(Ptr));
Secondary.deallocate(Options, BlockBegin);
}
}
The procedure begins by setting the state as available, followed by a search for the ClassId (bearing in mind that ClassId == 0 is reserved for secondary allocations). The TSD is queried, subsequently leading to the deallocation of the block. Should certain caches become depleted, the primary allocator undertakes an evaluation to determine if any memory can be relinquished to the operating system (not shown here).
At this point, the path is the same as allocation. It fills the local_cache, drains it if its full, and drains returns as TransferBatch in shared Region 0.
The deallocate function in standalone/local_cache.c is :
bool deallocate(uptr ClassId, void *P) {
CHECK_LT(ClassId, NumClasses);
PerClass *C = &PerClassArray[ClassId];
// We still have to initialize the cache in the event that the first heap
// operation in a thread is a deallocation.
initCacheMaybe(C);
// If the cache is full, drain half of blocks back to the main allocator.
const bool NeedToDrainCache = C->Count == C->MaxCount;
if (NeedToDrainCache)
drain(C, ClassId);
// See comment in allocate() about memory accesses.
const uptr ClassSize = C->ClassSize;
C->Chunks[C->Count++] =
Allocator->compactPtr(ClassId, reinterpret_cast<uptr>(P));
Stats.sub(StatAllocated, ClassSize);
Stats.add(StatFree, ClassSize);
return NeedToDrainCache;
}
And finally drain function:
NOINLINE void drain(PerClass *C, uptr ClassId) {
const u16 Count = Min(static_cast<u16>(C->MaxCount / 2), C->Count);
Allocator->pushBlocks(this, ClassId, &C->Chunks[0], Count);
// u16 will be promoted to int by arithmetic type conversion.
C->Count = static_cast<u16>(C->Count - Count);
for (u16 I = 0; I < C->Count; I++)
C->Chunks[I] = C->Chunks[I + Count];
}
The secondary allocator
The secondary allocator is simpler than the primary. This blogpost doesn't dive in details. Basically, each allocation is backed by a call to mmap, this allocation is surrounded by guard pages. There is also a cache and no quarantine, so you can get a previously allocated pointer:
[Pixel 7::myprogram ]-> a = malloc(0x20000)
"0xb4000076d4447000"
[Pixel 7::myprogram ]-> free(ptr(a))
[Pixel 7::myprogram ]-> a = malloc(0x20000)
"0xb4000076d4447000"
[Pixel 7::myprogram ]->
Is there room left for exploitation?
With the foundational aspects of Scudo now understood, we can look into potential attack scenarios. Both the Scudo and Android documentation affirm resilience against heap overflow, protection against use-after-free and double-free vulnerabilities. Furthermore, the shuffling of blocks before allocation also raises the overall security level.
In this technical exploration, we will check those protections from the perspective of an exploit developer. Our goal is to assess their effectiveness and validate the claims made about their resilience.
Scudo is resilient against heap overflow
When dealing with memory overflows within the context of Scudo, it's crucial to understand how different overflow sizes are handled. When an overflow exceeds 0x40000 bytes, it will extend beyond the allocated Region and eventually reach a guard page, causing the process to terminate abruptly. However, for smaller overflows, there remains a viable avenue for exploitation. It's essential to note that a small overflow operation can overwrite the headers of subsequent memory chunks. If a block's header is modified by such an overflow, the program will terminate due to the integrity checks performed by the free function when it is invoked.
As an exploit developer, you face two primary options when dealing with small overflows. The first option involves the complex task of recreating a valid header after the overflow, which can be a challenging and time-consuming endeavor. The second option offers a simpler approach: given that all checks are conducted by the free function, your objective should be to prevent any overflowed blocks from being freed after the overflow occurs.
Scudo protects against use-after-free
This statement raises a perplexing concern as there appears to be no evident defense mechanism within the codebase to mitigate this scenario. The process of allocating a chunk of memory, performing operations on it, freeing it, and still accessing the data appears unrestricted.
It's possible that this statement is related to the concept of quarantine, which could potentially address such issues. However, it's noteworthy that this feature is not activated within the Android environment.
For exploit developers, investigating the possibility of Use-After-Free vulnerabilities is a valid option, given the observations made here.
Scudo protects against double free vulnerabilities
Scudo proves to be efficient when it comes to detecting instances of double frees. With state bits located in the header, Scudo can readily identify a situation where a block that has already been freed is subjected to further deallocation attempts, promptly halting the process to prevent any potential misuse.
However, for exploit developers, the concept of a 'double free' takes on a subtly different connotation. Their objective is often to reallocate the chunk of memory between the first and second free operations. In this specific scenario, Scudo's built-in safeguards do not provide protection. The second free operation successfully passes all checks since the header has been reconstructed through the reallocation process.
To clarify, it is essential to understand that while Scudo excels in detecting double free scenarios, it may not be a foolproof defense against a determined exploit developer seeking to exploit a double free vulnerability.
Scudo randomizes allocations
Scudo employs a strategy aimed at increasing the difficulty for exploit developers by introducing randomness into memory allocations. As we've observed, consecutive allocations are intentionally made non-contiguous, preventing attackers from establishing a predefined order within heap memory.
For exploit developers, this defense mechanism poses a significant challenge. Many exploits rely on the ability to align vulnerable chunks with targeted ones in a predictable manner.
Upon analyzing the code, we uncovered an interesting detail: the shuffling of memory blocks only occurs after processing four consecutive TransferBatches. This means that it remains possible for an attacker to fill all four of these TransferBatches and then secure four additional TransferBatches positioned after the previous set. This strategy ensures that an allocation will be located after another one, potentially providing a workaround to the non-contiguous allocation challenge posed by Scudo's defense.
Conclusion
Undoubtedly, Scudo significantly elevates the security level. While it's true that its defenses can potentially be circumvented, the cost is steep: an attacker must meticulously control the allocations, requiring the ability to allocate numerous chunks, retain them, and release them at right moments. Attackers do need to find additional attack primitives, yet there remains room to craft awesome exploits.
- 1. Region 0 is not tied in any way with the ClassId 0 (used for secondary allocator).
- 2. This alignement of 16 bytes explain the 8 bytes padding of the header in order to be aligned.
- 3. The global size can be calculated as the difference between the higher and the lower address: 0x7cdf782000-0x7acf782000 = 33*2**28 which is exactly NumClasses * 2^RegionSizeLog bytes as expected