VMware ESXi Forensic with Velociraptor
If you are a regular Velociraptor user, you'll no doubt have noticed the introduction of new features since release 0.7.1 that extend its forensic capabilities on various systems. If not, this article will show you how to leverage those new features in order to perform forensic analysis of a VMware ESXi hypervisor.
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Introduction
During our investigations, we have come across more and more VMware ESXi hypervisors. These are being increasingly targeted by attackers, as they can quickly compromise an entire information system. About a year ago, we discovered a new fork of Babuk ESX Encryptor and since then, new threats have emerged, including ransomware from the threat actor LockBit targeting ESXi hypervisors.
Version 0.7.1 of Velociraptor introduced a number of new features that give us capabilities to analyze a VMware ESXi hypervisor with Velociraptor.
In this article, we'll look at how to make the most of these features.
For the purpose of this article, all tests have been made on VMware ESXi version 7.0.3 .
Overview
In order to fully understand the article, let's review a few concepts related to VMware ESXi and Velociraptor.
VMware ESXi: structure and artifacts
VMware ESXi is a bare-metal hypervisor. It is widely used to virtualize part or all of the information system. It often hosts application servers or even the Active Directory. The operating system is based on a custom POSIX kernel, the VMkernel, that uses several UNIX utilities through BusyBox. This means we can find UNIX file system organization and hierarchy, classic utilities (ls, cp, ssh, ...) and configuration management. As a result, from a forensic point of view we can find classic artifacts available on UNIX/Linux systems (command line history for example), as well as artifacts more specific to virtualization features.
VMware ESXi: forensic tools
At the moment, it is hard to find truly reliable tools for VMware ESXi collection, triage and analysis. In general, we have to use custom scripts in order to perform collection, then triage and analysis. Most of them focus particularly on logs, which remain the most important source of information during an incident. For example, the ANSSI (the french national cybersecurity agency) designed a tool called DFIR4vSphere which rely on the PowerShell module PowerCLI to retrieve logs and the ESXCLI command line tool to fetch specific artifacts. From our point of view, this is the most comprehensive open source tool available.
Velociraptor: description and supported systems
Velociraptor works like an EDR (Endpoint Detection and Response) tool, with a central console and agents deployed on client machines. Unlike a conventional EDR, it does not have a database of signatures and malicious behavior. In short, it allows you to perform specific actions on the host, such as retrieving specific files, checking for the presence of specific elements in certain artifacts, etc. Obviously, it's possible to do more things with it, but for those who don't know this tool, it gives you an idea of its capabilities.
Currently, Velociraptor agent can be deployed on UNIX (FreeBSD), Linux, Windows and MacOS. As you might guess, despite many similarities with POSIX systems, the Velociraptor agent can't be deployed on a VMware ESXi. Many dependencies are not satisfied. As the source code is available, it would be possible to try to compile directly for the target system, but we haven't tried this approach because of too many dependencies issues.
Velociraptor: SSH Accessor and Notebook template
Since the version 0.7.1, Velociraptor has introduced several new features that make it possible to analyze a VMware ESXi from Velociraptor without the need to deploy an agent: the new SSH accessor and notebook templates.
Velociraptor's author defines an accessor as follows:
Velociraptor accesses filesystems by way of an accessor. You can think of an accessor as a specific driver that VQL can use to open a path. All VQL plugins or functions that accept files will also accept an accessor to use to open the file.
Basically, an accessor can be seen as a driver for accessing a machine's filesystem Instead of deploying an agent on a system, so in that case we use an SSH connection to access and interact with the system.
As this new accessor has not been designed for use in a VQL, notebooks are required to use it. Notebooks are interactive documents that can be edited to modify the content of a VQL query according to the result, used for post-processing or simply to test a query before creating a custom VQL artifact. Notebook templates, like VQL artifacts, can be used to create easily reusable notebook models.
Even if this accessor has been designed to be used with a notebook, it is possible to use it with VQL artifacts.
In the next section, we'll take a look at how we can take advantage of these new features in order to collect, triage and analyze VMware ESXi's artifacts in two different situations: a direct access and indirect access. And also why it can be more powerful than custom scripts with various examples.
First use-case: Direct Access through Notebook
In this case, we assume that we can establish a direct SSH connection between the hypervisor and our host.
SSH ACCESSOR
In order to use the SSH ACCESSOR, we need some parameters:
- hostname: the IP address and the associated port
- user: account used to perform authentication, this user must have high privileges
- authentication method: user password or private SSH key
These parameters are then passed to the variable SSH_CONFIG to initiate the connection. In the example below, we use password authentication, but it is recommended to use SSH key authentication.
// Parameters to provide
LET ssh_hostname = "10.0.0.8:22"
LET ssh_username = "root"
LET ssh_password = "password"
LET ssh_keyfile = ""
// SSH Connection: password use
LET SSH_CONFIG <=dict(
hostname=ssh_hostname,
username=ssh_username,
password=ssh_password)
LET _ <= remap(config='''
remappings:
- type: mount
from:
accessor: ssh
on:
accessor: auto
''')
So we create an empty notebook and define our SSH configuration with remapping. Remapping enables transparent use of the SSH accessor in the scope (i.e. the global environment). This means we don't have to specify it every time we use a plugin like glob, for example.
As mentioned earlier, the most important artifacts are the logs, so we'll see step by step how to collect them.
Retrieving logs
Identify log location
By default, VMware ESXi logs are stored in the /scratch/log folder. When examining the filesystem tree, this is a link to another folder /var/lib/vmware/osdata/locker/log. Except that this folder is also a link to another folder: /vmfs/volumes/{uid}/log. So, we need a reliable way of identifying this location, as Velociraptor doesn't seem to be able to follow the link to identify the actual location. This may be specific to the file system, VMFS.
Fortunately for us, the /etc/vmsyslog.conf configuration file stores the default location for this directory.
The following extract shows the correspondence between the different locations:
- the file system hierarchy, we can observe several link to
/var/lib/vmware/osdata folder
[root@localhost:~] ls -l
total 1101
...
drwxr-xr-x 16 root root 512 Jan 4 14:34 dev
drwxr-xr-x 1 root root 512 Jan 4 14:28 etc
drwxr-xr-x 1 root root 512 Jan 4 12:21 include
drwxr-xr-x 1 root root 512 Jan 4 12:21 lib
drwxr-xr-x 1 root root 512 Jan 4 12:21 lib64
-rw-r--r-- 1 root root 75448 Jan 4 12:21 local.tgz
-r--r--r-- 1 root root 90112 Jan 3 17:31 local.tgz.ve
lrwxrwxrwx 1 root root 29 Jan 4 12:23 locker -> /var/lib/vmware/osdata/locker
drwxr-xr-x 1 root root 512 Jan 4 12:21 opt
drwxr-xr-x 1 root root 131072 Jan 4 14:34 proc
lrwxrwxrwx 1 root root 28 Jan 4 12:23 productLocker -> /locker/packages/vmtoolsRepo
lrwxrwxrwx 1 root root 4 Jun 15 2023 sbin -> /bin
lrwxrwxrwx 1 root root 22 Jan 4 12:23 scratch -> /var/lib/vmware/osdata
lrwxrwxrwx 1 root root 28 Jan 4 12:23 store -> /var/lib/vmware/osdata/store
....
- the folder
/var/lib/vmware/osdatais a redirection for the real volume file system
[root@localhost:~] ls -l /var/lib/vmware/
total 16
drwxr-xr-x 1 root root 512 Jan 4 12:21 configstore
drwxr-xr-x 1 root root 512 Jun 15 2023 firstboot
drwxr-xr-x 1 root root 512 Jan 4 12:23 hostd
lrwxrwxrwx 1 root root 49 Jan 4 12:23 osdata -> /vmfs/volumes/658c9bfb-c80d6a8e-1a1e-525400792eb1
[root@localhost:~] cat /etc/vmware/locker.conf
/vmfs/volumes/658c9bfb-c80d6a8e-1a1e-525400792eb1 0
[root@localhost:~] readlink -f scratch/log/
/vmfs/volumes/658c9bfb-c80d6a8e-1a1e-525400792eb1/log
- from that point we can retrieve the real log location
[root@localhost:~] ls scratch/log/
LogEFI.log dpd.log hostd-probe.log loadESX.log storagerm.log vmkernel.log vsanfs.configdump.log
Xorg.log envoy.log hostd.log localcli.log swapobjd.log vmkeventd.log vsanfs.mgmt.log
apiForwarder.log epd.log hostdCgiServer.log metald.log syslog.log vmksummary.log vsanfs.vdfsop.log
...
[root@localhost:~] ls /vmfs/volumes/658c9bfb-c80d6a8e-1a1e-525400792eb1/log
LogEFI.log dpd.log hostd-probe.log loadESX.log storagerm.log vmkernel.log vsanfs.configdump.log
Xorg.log envoy.log hostd.log localcli.log swapobjd.log vmkeventd.log vsanfs.mgmt.log
apiForwarder.log epd.log hostdCgiServer.log metald.log syslog.log vmksummary.log vsanfs.vdfsop.log
...
Instead of the default location, a datastore is often configured to store ESX logs. In this case, the location of the logs can be identified using the variable logdir in the file /etc/vmsyslog.conf :
[root@localhost:~] cat /etc/vmsyslog.conf
[DEFAULT]
...
check_ssl_certs=true
logdir=/scratch/log
remote_host_max_msg_len=1024
size=1024
loghost=<none>
audit_log_remote=false
audit_log_dir=/scratch/auditLog
standard_message_threads_per_socket=2
audit_log_local=false
standard_message_memory_pool_size=40
audit_record_memory_pool_size=1
[vmsyslog]
audit_record_memory_pool_size=1
logdir=/vmfs/volumes/658d55ea-d1bf6498-33a9-525400792eb1/systemlogs
The vmsyslog.conf file contains the log configuration. Even if a datastore is configured to store logs, the default entry is always present. This entry will contain system logs until the location is changed. For the purpose of this article, we didn't test remote logging.
File parsing
LET config_file_regex = "logdir="
LET file_to_parse = SELECT OSPath FROM glob(globs=config_file)
LET parse_config_file = SELECT * FROM foreach(row=file_to_parse,
query={
SELECT Line FROM parse_lines(filename=OSPath)
WHERE
Line =~ config_file_regex
})
LET log_path = SELECT split(string=Line,sep='=')[1] + "/*" AS FullPath FROM parse_config_file
This is the part that usually takes the longest. We need to retrieve the file we wish to analyze with the glob plugin.
Then we go through the file line by line using the parse_lines plugin and identify the lines corresponding to the element we're looking for using our config_file_regex variable which contains our keyword "logdir". Finally, we retrieve the contents of the variable and add "/*" to specify that we wish to retrieve all the files in this folder.
Log location selection
LET scratch = SELECT FullPath FROM log_path WHERE FullPath =~ "scratch"
LET vmfs = SELECT FullPath FROM log_path WHERE FullPath =~ "vmfs"
LET real_path = SELECT * FROM if(condition=vmfs,
then=vmfs,
else=real_scratch_path
)
When we parse our vmsyslog.conf configuration file, we consider the case where there are several possible entries distinguished by the keywords vmfs and scratch. If the vmfs variable is not empty, this means that a specific location has been defined for the logs otherwise we take the default location.
Now that we have all we need, i.e the location of the logs and the accessor defined, the rest of the request is quite similar to retrieving files from Velociraptor. All that remains is to automate the process by creating a notebook template.
Notebook template: artifact creation
The aim of our artifact is to retrieve logs from our VMware ESXi hypervisor. To do this, we'll create a new VQL artifact and change our CLIENT type to NOTEBOOK.
This results in the following, with variables config_file and config_file_regex included as parameters:
name: Custom.ESXi.RetrieveLogs
description: |
VMware ESXi logs retrieval with Notebook and SSH Accessor
# Can be CLIENT, CLIENT_EVENT, SERVER, SERVER_EVENT or NOTEBOOK
type: NOTEBOOK
sources:
- notebook:
- type: markdown
template: |
This notebook is used to retrieve logs from an ESXi hypervisor.
Information to provide: ESXi IP address, the port used for SSH, a user account with means of authentication (password or SSH key).
- type: vql
name: ESXi Upload logs
template: |
// Parameters to provide
LET ssh_hostname = ""
LET ssh_username = ""
LET ssh_password = ""
LET ssh_keyfile = ""
LET config_file = "/etc/vmsyslog.conf"
LET config_file_regex = "logdir="
// SSH Connection: password use for this example
LET SSH_CONFIG <=dict(
hostname=ssh_hostname,
username=ssh_username,
password=ssh_password)
LET _ <= remap(config='''
remappings:
- type: mount
from:
accessor: ssh
on:
accessor: auto
''')
LET file_to_parse = SELECT OSPath FROM glob(globs=config_file)
LET parse_config_file = SELECT * FROM foreach(row=file_to_parse,
query={
SELECT Line FROM parse_lines(filename=OSPath)
WHERE
Line =~ config_file_regex
})
LET log_path = SELECT split(string=Line,sep='=')[1] + "/*" AS FullPath FROM parse_config_file
LET scratch = SELECT FullPath FROM log_path WHERE FullPath =~ "scratch"
LET vmfs = SELECT FullPath FROM log_path WHERE FullPath =~ "vmfs"
//Retrieve real path of scratch
LET scrach_location = SELECT OSPath FROM glob(globs="/etc/vmware/locker.conf")
LET parse_scrach_location = SELECT * FROM foreach(row=scrach_location,
query={
SELECT Line FROM parse_lines(filename=OSPath)})
LET real_scratch_path = SELECT split(string=Line,sep=' ')[0] +"/log/*" AS FullPath FROM parse_scrach_location
LET real_path = SELECT * FROM if(condition=vmfs,
then=vmfs,
else=real_scratch_path
)
LET results = SELECT OSPath, Size,
Mtime As Modifed,
type AS Type,
upload(file=OSPath,
accessor=accessor,
ctime=Ctime,
mtime=Mtime) AS FileDetails
FROM glob(globs=real_path.FullPath, accessor="ssh")
SELECT OSPath, Size, Modifed, Type,
FileDetails.Path AS ZipPath,
FileDetails.Md5 as Md5,
FileDetails.Sha256 as SHA256
FROM results
This will result in the creation of a new artifact (2) of notebook template type (1).

From that point, we could launch our Notebook from the "Notebook" menu by selecting our Custom.ESXi.RetrieveLogs just like we would launch a classic VQL artifact:

Notebook template: execution and results
All we have to do now is fill in the fields and save our notebook to launch it. We need to specify the port associated with the IP address. For this example, we chose password authentication.
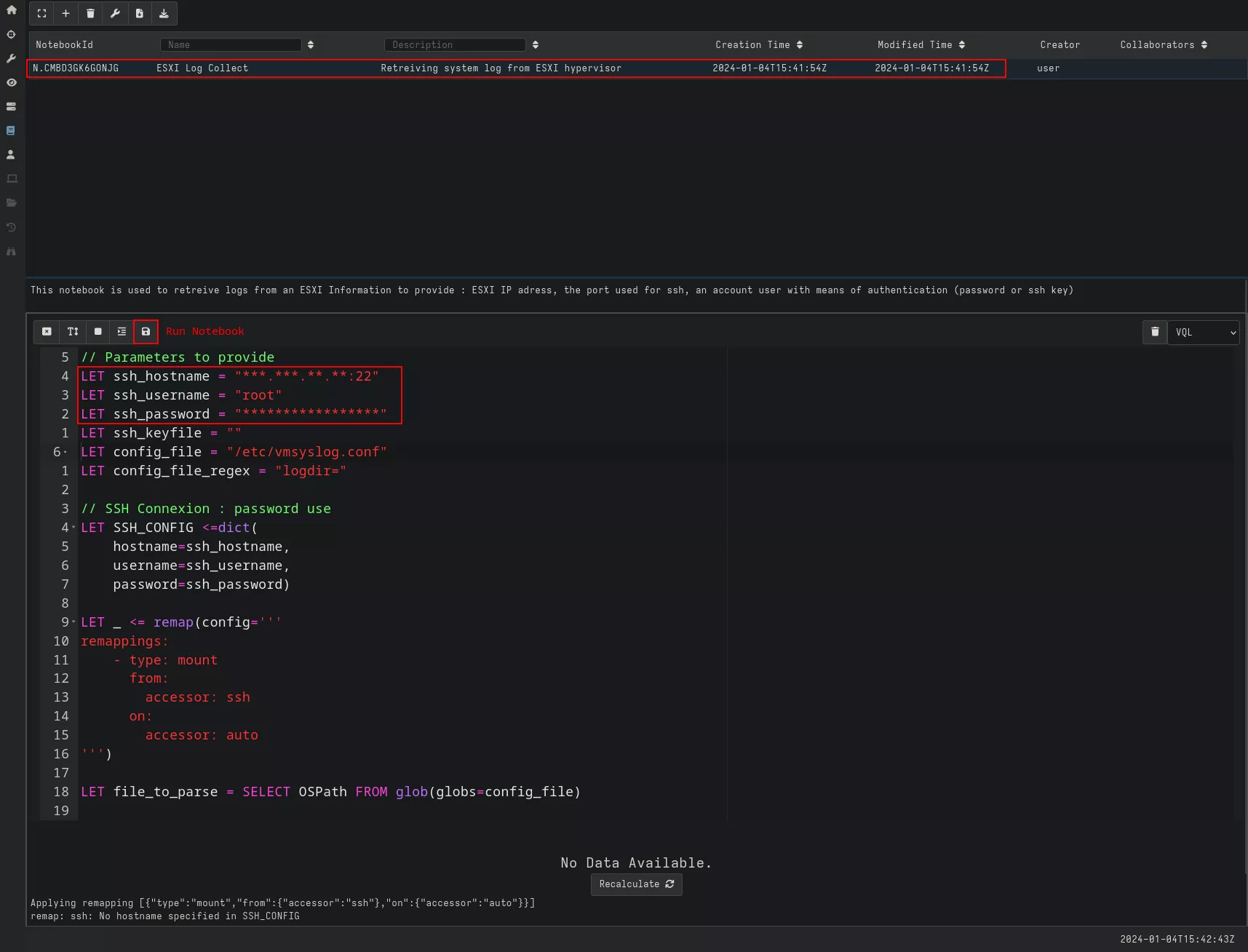
Running our notebook gives us a list of available logs, their sizes, and the date they were last modified/updated. We can then see how many logs have been retrieved (1) and download them for analysis (2).
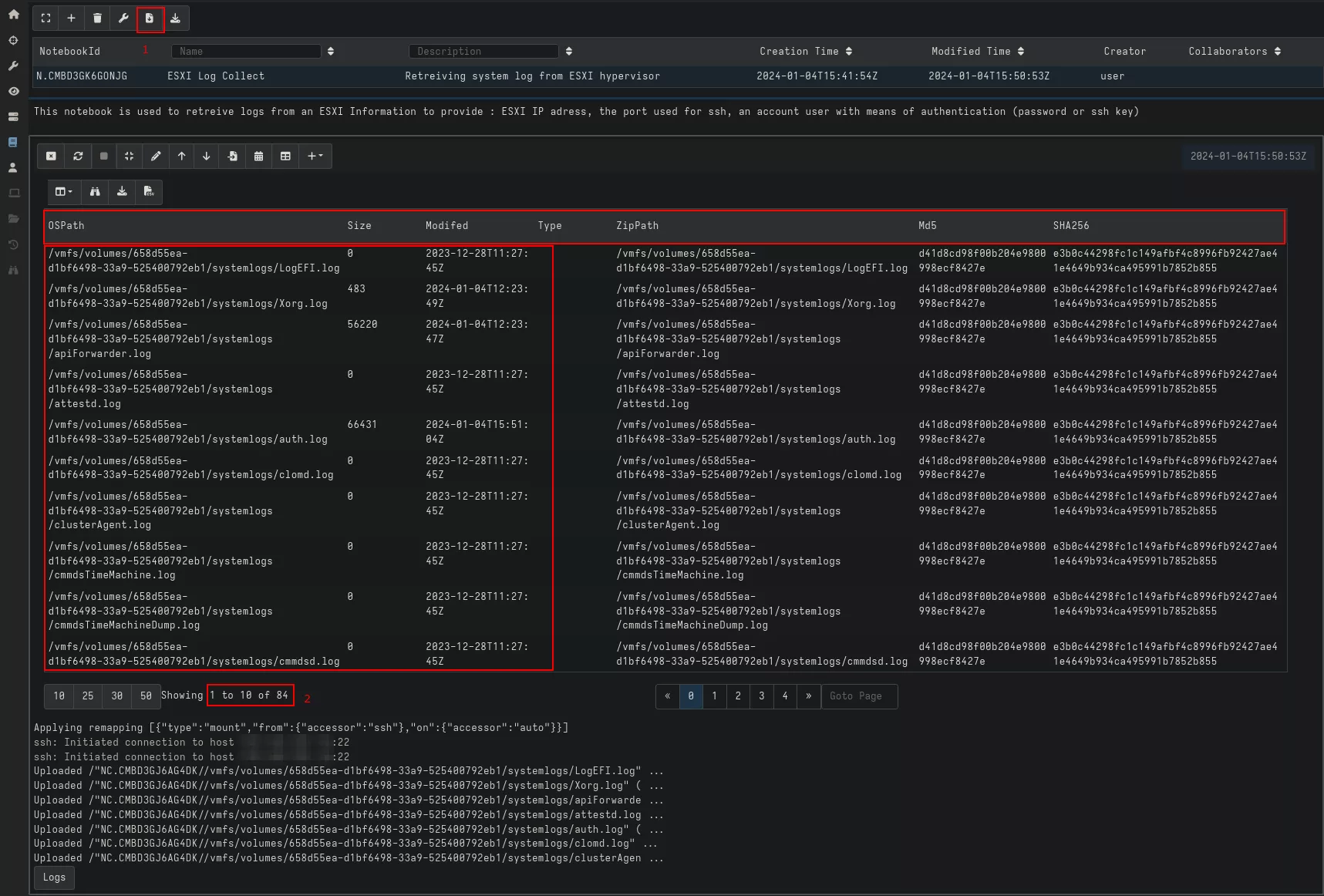
Notebook expansion
One of the main advantages of notebook is the ability to run multiple queries inside the same notebook. Which means several artifacts can be processed at the same time. And this is where Velociraptor becomes more interesting than a custom script because we can use classic Linux artifacts already available with it.
For example, we can add the following line at the end of our notebook:
...
SELECT OSPath, Size, Modifed, Type,
FileDetails.Path AS ZipPath,
FileDetails.Md5 as Md5,
FileDetails.Sha256 as SHA256
FROM results
SELECT * FROM Artifact.Linux.Sys.Pslist()
This will give the following results with logs collection and a list of running processes:
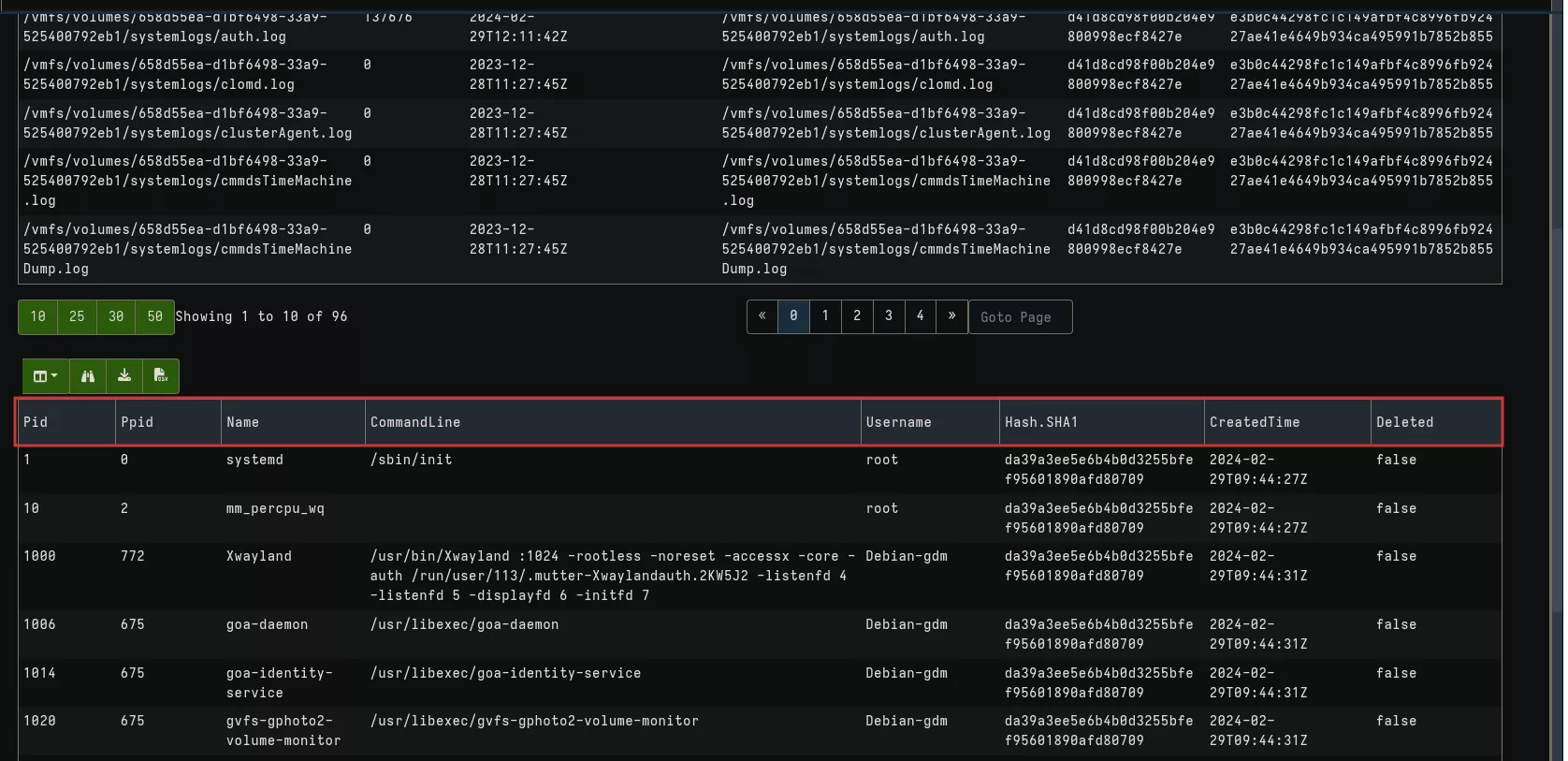
In the next section, we'll see how to create a client artifact and explore other Linux and ESXi artifacts.
Second use-case: Indirect Access with a proxy machine
In this case, we assumed that another machine must be used as a proxy to reach our hypervisor.
Client artifact: proxy machine
As previously mentioned, SSH Accessor has been designed to be used with Notebook. But there is situation where direct access to the hypervisor is not possible. This means, client artifact can't be used as they have been designed to be run by the Velociraptor agent on the target machine.
In order to solve this problem, we used a Linux machine, with a Velociraptor agent on it, that can connect directly to the hypervisor via SSH, through an administrator or proxy machine, for example
In that case, to create a client artifact, we'll define default parameters for the accessor and optional parameters for our artifacts. Then we'll use the previous SSH_CONFIG variable and remapping in the query statement (i.e : the core of our request).
Client artifact: proxy machine example
The hypervisor includes a firewall that is enabled by default. It is configured to block incoming and outgoing traffic, except for some services. This configuration can be modified, for example to authorize certain IP addresses to access the management console or the remote SSH connection. It can even be used to establish persistence by opening a port for a new installed service through a VIB bundle (an ESXi software package) like the VirtualPita backdoor. The state of the firewall ruleset can be found in the following XML file: /etc/vmware/firewall/service.xml. Prior to ESXi version 7, custom firewall rules could be modified by editing the service.xml file. In later versions of ESXi, new rules can be added only through a partner-created VIB (which means, in case of doubt, checking all installed VIB modules might be useful).
In the following example, we create a client artifact to identify authorized services on the hypervisor firewall:
name: Custom.ESXi.Firewall
author: "NN"
description: |
This artifact is used to retrieve ESXi Firewall configuration and identify suspicious services enabled.
type: CLIENT
parameters:
- name: firewall_file
description: firewall configuration
default: /etc/vmware/firewall/service.xml
- name: ssh_hostname
description: ESXi IP address and port
default:
- name: ssh_username
description: account for SSH connection
default:
- name: ssh_password
description: account password
default:
- name: ssh_key
description: account private SSH key
default:
sources:
- query: |
LET SSH_CONFIG <=dict(
hostname=ssh_hostname,
username=ssh_username,
password=ssh_password
)
LET _ <= remap(config='''
remappings:
- type: mount
from:
accessor: ssh
on:
accessor: auto
''')
LET XML = SELECT parse_xml(file=OSPath).ConfigRoot FROM glob(globs=firewall_file)
SELECT _value.id AS Service,
_value.rule.direction AS direction,
_value.rule.protocol AS protocol,
_value.rule.port AS port,
_value.enabled AS enabled
FROM foreach(row=parse_xml(accessor="ssh", file=firewall_file).ConfigRoot.service)
This query collects and parses an XML file with an entry per service that may have one or more rules, with the following information:
- service: service name
- direction: inbound or outbound
- protocol: tcp or udp
- port : number and, src or dst
- enable: true (activate) or false
This gives us the following result:
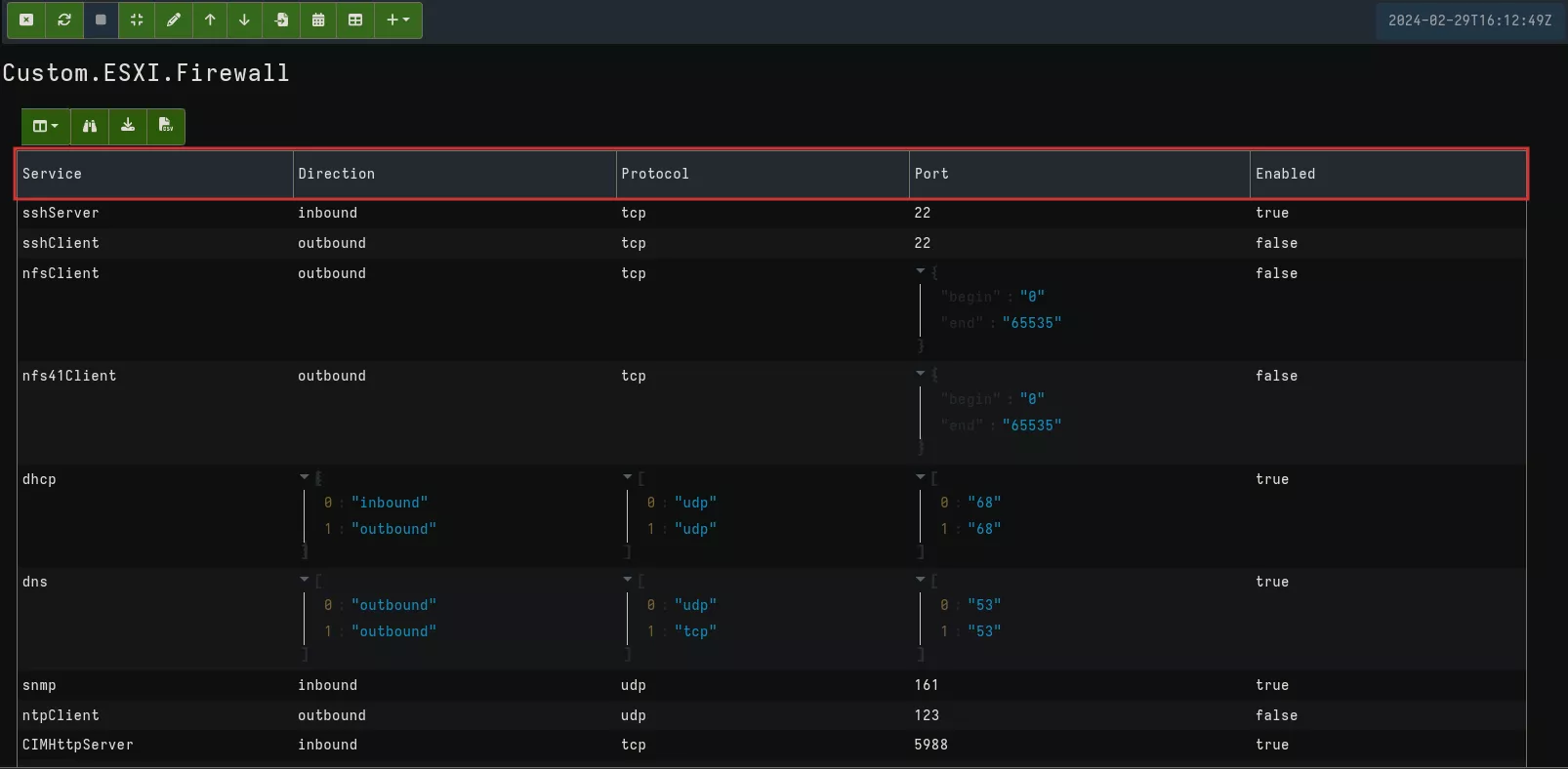
In our case, we're particularly interested in the rule applied by filtering Enabled on true.
During our tests, we were unable to determine whether it is possible to obtain the whitelisted IP addresses by this means.
Client artifact: chaining artifacts
Having one query for each artifact could be interesting, but rather than launching artifacts one by one, we prefer to combine all our artifacts into a single query, as we'll do with a collector.
To do so, we have two options:
- Create a query which calls each artifact.
- Create a query with all artifacts inside.
To avoid having to define SSH_Accessor and parameters every time, we prefer the second approach.
Our client artifact will consist of three parts:
- Parameters for SSH connection and elements specific for each artifact.
- The definition of our accessor available for each query.
- A query for each artifact.
This will give us a global artifact with a structure similar to the following example:
name: Custom.ESXi.Global
author: "NN"
description: |
ESXi Collector
type: CLIENT
parameters:
- name: ssh_hostname
description: ESXi IP address and port
default:
- name: ssh_username
description: XXX
...
export: |
LET SSH_CONFIG <=dict(
hostname=ssh_hostname,
username=ssh_username,
password=ssh_password
)
LET _ <= remap(config='''
remappings:
- type: mount
from:
accessor: ssh
on:
accessor: auto
''')
sources:
- name: PS EXSi
description: Processes list
query: |
SELECT * FROM Artifact.Linux.Sys.Pslist()
- name: ESXi Users
description: Users list
query: |
SELECT * FROM Artifact.Linux.Sys.Users()
- name: ESXi Firewall
description: ESXi Firewall
query: |
LET XML = SELECT parse_xml(file=OSPath).ConfigRoot FROM glob(globs=firewall_file)
...
The export directive makes our variable SSH_CONFIG and our remapping available for each query. And each query has its own request.
Client artifact: adapting existing artifacts
The ability to reuse existing artifacts is one of Velociraptor's great strengths. However, some artifacts are not compatible or need to be adapted. This is the case, for example, with the Linux.Syslog.SSHLogin which parses authentication logs to determine all SSH login attempts.
This artifact uses two parameters:
syslogAuthLogPath: location of logs to be parsed.SSHGrok: Grok expression for parsing SSH auth lines.
The log authentication of a classic Linux has the following structure:
...
Feb 15 20:47:15 EK2 sshd[3205]: Failed password for invalid user user1 from 192.168.111.162 port 50640 ssh2
Feb 15 20:47:22 EK2 sshd[3207]: Failed password for invalid user user1 from 192.168.111.162 port 60646 ssh2
Feb 15 20:47:36 EK2 sshd[3209]: Failed password for invalid user user1 from 192.168.111.162 port 38444 ssh2
Feb 15 20:47:39 EK2 sshd[3211]: Failed password for invalid user user1 from 192.168.111.162 port 38456 ssh2
Feb 15 20:52:06 EK2 sshd[3324]: Accepted password for test from 192.168.111.4 port 55218 ssh2
Feb 15 20:52:22 EK2 sshd[3335]: Failed password for root from 192.168.111.4 port 59258 ssh2
...
The Grok expression used to parse those entries is as follows:
%{SYSLOGTIMESTAMP:Timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}: %{DATA:event} %{DATA:method} for (invalid user )?%{DATA:user} from %{IPORHOST:ip} port %{NUMBER:port} ssh2(: %{GREEDYDATA:system.auth.ssh.signature})?
The log authentication of an ESXi hypervisor has the following strucutre:
2024-01-05T18:33:12.859Z sshd[527525]: error: PAM: Authentication failure for root from 192.168.122.185
2024-01-05T18:33:16.235Z sshd[527530]: Accepted keyboard-interactive/pam for root from 192.168.122.185 port 58088 ssh2
2024-01-05T18:41:45.685Z sshd[527572]: Accepted password for root from 192.168.122.185 port 49494 ssh2
2024-01-05T18:41:45.811Z sshd[527578]: Accepted password for root from 192.168.122.185 port 49510 ssh2
2024-01-05T18:43:54.391Z sshd[527590]: Accepted password for root from 192.168.122.185 port 60394 ssh2
2024-01-05T18:43:54.513Z sshd[527596]: Accepted password for root from 192.168.122.185 port 60408 ssh2
So to make it work, the two parameters (the location path and the Grok expression) must be modified.
For the first parameter, we can take the first artifact we've seen to retrieve logs and adapt it to have the location. The second parameter, on the other hand, is slightly more complicated. You may have noticed that the structure of failures and successes is similar for a classic Linux while for ESXi it's different. At least from a Grok's perspective.
So we need to create two Grok expression one for successes, one for failures. All of this results into an artifact with a structure similar to the following structure:
name: Custom.ESXi.Global
author: "NN"
description: |
ESXi Global Forensic
type: CLIENT
parameters:
- name: config_file
description: configuration file for log location
default: "/etc/vmsyslog.conf"
- name: config_file_regex
description: regex to match entry for location
default: "logdir="
- name: auth_log
description: authentication log location
default:
- name: ssh_hostname
description: ESXi IP address and port
...
export: |
LET SSH_CONFIG <=dict(
...
sources:
- name: ESXiLog
description: Retrieve ESXi logs
query: |
LET file_to_parse = SELECT OSPath FROM glob(globs=config_file)
...
LET auth_log = SELECT OSPath FROM glob(globs=real_path.FullPath, accessor="ssh") WHERE OSPath =~ "auth.log"
...
...
- name: SSH Login
description: SSH Authentication failures and sucesses
query: |
LET SSHGrokFail="%{TIMESTAMP_ISO8601:Timestamp} %{SYSLOGPROG}: error: PAM: Authentication %{DATA:event} for %{DATA:user} from %{IPORHOST:ip}"
LET SSHGrokSucces="%{TIMESTAMP_ISO8601:Timestamp} %{SYSLOGPROG}: %{DATA:event} %{DATA:method} for %{DATA:user} from %{IPORHOST:ip} port %{NUMBER:port} ssh2(: %{GREEDYDATA:system.auth.ssh.signature})?"
SELECT timestamp(string=Event.Timestamp) AS Time,
Event.event AS Result,
Event.ip AS IP,
Event.method AS Method,
Event.user AS Account,
OSPath AS Location_file
FROM foreach(
row={
SELECT OSPath FROM glob(globs=auth_log.OSPath)
}, query={
SELECT * FROM combine(
fail={
SELECT grok(grok=SSHGrokFail, data=Line) AS Event, OSPath
FROM parse_lines(filename=OSPath)
WHERE Event.program = "sshd"
},sucess={
SELECT grok(grok=SSHGrokSucces, data=Line) AS Event, OSPath
FROM parse_lines(filename=OSPath)
WHERE Event.program = "sshd"
}
)
})
We've made two small optimizations:
- We define a parameter
auth_logto store authentication log location during the execution of the first artifact. - We
combinefailure and success into one table, although it may be intersting to have them separately.
This results into the follow result:

As we are not experts of Grok expression, if you have any idea for improvement, don't hesitate to reach out to us !
Conclusion
In this article we've tried to explore the possibilities offered by Velociraptor's new features. If we were to summarize the concepts presented in this article, the key points to remember would be:
- The
SSH_ACCESSORlets us interact with a VMware ESXi hypervisor without an agent through an SSH connection. - The
SSH_ACCESSORcan be used directly with a Notebook. - The SSH_
ACCESSORcan be used indirectly with VQL artifacts through a Linux proxy machine on which an agent is deployed. - Existing Linux artifacts can be reused with the hypervisor, with some modifications in some cases.
- Several detailed examples are provided to illustrate how to use the various facets of this functionality.
- Artifacts can be chained into one global query.
To conclude, we've seen that we can use all of Velociraptor's abilities to perform collect, triage and analyze an ESXi hypervisor. This makes it possible to go further than a script in terms of capacity and scalability. Obviously, there are still many forensic aspects of ESXi to explore, particularly command execution. For some unknown reason, we were unable to use some ESXi specific tools yet such as esxcli which could provide us with other interesting information.
More generally, the approach used to analyze ESXi can be applied to other systems that don't support Velociraptor agents but have an SSH connection.